Automating Enhanced Due Diligence in Regulated Applications
Learn how automating EDD can streamline compliance, improve accuracy, and reduce costs in regulated industries.



Enhanced due diligence (EDD) is a process that helps regulated industries identify and mitigate risks. Unlike know your customer (KYC), EDD requires a deeper look into an individual or entity's background, including financial activities, geographic locations, and ownership structures. It helps organizations meet anti-money laundering (AML) regulations and combats fraud, corruption, and terrorism financing.
As regulations become more stringent, applying and managing EDD becomes increasingly difficult. Many organizations struggle with manual, time-consuming processes that are prone to human error and inefficiencies.
Automated systems offer a faster, more reliable, and scalable way to gather and analyze due diligence data, ensuring compliance without sacrificing efficiency. For developers, automating EDD is an opportunity to streamline compliance workflows via API-driven solutions.
In this blog, you'll learn how automating EDD can help streamline compliance, improve accuracy, and reduce costs.
Understanding EDD
EDD involves collecting and analyzing detailed data from a variety of sources, including sanctions lists, politically exposed person (PEP) databases, transaction histories, and adverse media. EDD success comes from the quality and diversity of these data sources. Inaccurate or missing information can cause you to miss red flags and run into regulatory noncompliance.
Additionally, data formats can vary, from structured APIs (JSON, XML, etc.) to unstructured documents. This often creates challenges when it comes to integrating and processing the information.
CDD vs. EDD
Customer due diligence (CDD) is a foundational layer of compliance, and while often conflated with EDD, it uses different processes. It verifies customers' identities and evaluates risk using simple checks, such as reviewing IDs, basic background checks, and sanctions list searches. EDD goes further, using advanced data analytics, real-time processing, and more complex data sources to assess risks more comprehensively.
EDD processes must account for scenarios with transactions involving PEPs, links to high-risk jurisdictions, or even large payments from unknown third parties. These situations require technical systems that can manage large volumes of data, perform real-time analysis, and use adaptive rules engines to keep up with changing compliance requirements.
Challenges of Manual EDD Processes
Because EDD is a complex process, carrying it out manually can be challenging.
Difficulties Integrating Disparate Data Sources
Manual EDD processes often struggle to integrate disparate data sources, particularly when legacy systems and siloed databases are involved. For developers who have to implement or maintain these systems, inconsistent data formats and the lack of standardized APIs complicate integration efforts.
Brittle Pipelines
Pulling data from sanctions lists, PEP databases, transaction logs, and adverse media often involves building custom connectors and extensive preprocessing. This can lead to brittle pipelines that are difficult to scale or adapt. These integration challenges slow down development and introduce vulnerabilities in compliance workflows, as even minor data mismatches or delays can result in incomplete risk assessments around the entities in question.
Maintaining Complex Rule Sets
EDD involves nuanced risk-scoring algorithms and thresholds that may vary based on jurisdiction, customer profile, and transaction type. Teams need to regularly update these rules to align with changing regulations and business needs. This process is prone to error and miscommunication.
Scaling and Performance Bottlenecks
Manual processes often struggle with scalability. Handling large data sets and performing real-time risk evaluations manually leads to performance bottlenecks and makes it hard to meet growing regulatory demands. This underscores the need for automated, API-driven solutions.
Automating EDD
Let's take a look at the process of automating EDD pipelines and what you need to keep in mind when you do.
Architectural Considerations for Automated EDD
Start by choosing a technical architecture to design your automated EDD pipelines in. When designing the architecture, you need to consider three key factors:
- Scalability: Your EDD pipeline needs to be scalable across your target userbase. Scalability issues can lead to due diligence requests being delayed, potentially contributing to user churn.
- Flexibility: The EDD process for each organization is specific to its industry and function. To add to that, compliance requirements and regulatory laws often change frequently. Your EDD needs to be flexible enough to allow you to make changes to the process or its details as and when needed.
- Ability to handle real-time processing: Your EDD pipeline must offer support for real-time processing. This does not mean that you need to run all checks in real time before approving a user account; it means that your pipeline must be designed in a way that it carries out as many checks as it can in real time when signing up a user and triggers asynchronous background jobs for more detailed checks. While the background checks are being carried out, you can choose to allow the user to access a restricted version of your service. This can help immensely in situations where you don't need to carry out extensive checks for a user (such as those coming from low-risk jurisdictions).
Keeping these factors in mind, you can design your EDD pipeline using either (or even a mix of) microservices and event-based architecture types.
Microservices Architecture
Microservices architecture is a natural fit for EDD due to its modularity and ability to integrate diverse components like sanctions list checks, PEP database queries, and transaction history analysis. Each EDD component can function as an independent microservice, enabling developers to deploy, scale, and update each individually without disrupting the entire system.
For example, a microservice dedicated to querying sanctions lists can be optimized for high-speed API calls, while another for analyzing adverse media can use AI-powered natural language processing. This approach promotes agility and ensures that compliance systems remain adaptable to evolving regulatory requirements.
Event-Driven Architecture
Event-driven architecture is another potential approach for automating EDD, particularly for handling real-time data ingestion and processing. Technologies like message brokers (Kafka, RabbitMQ) can help event-driven systems process high volumes of compliance data asynchronously.
For instance, when a high-risk transaction is flagged, events can trigger additional checks, such as deep-dive risk scoring or enhanced identity verification, without delaying the overall process. This architecture is especially suitable for EDD scenarios that require immediate action, such as detecting suspicious activity involving high-risk jurisdictions.
However, implementing event-driven systems requires careful error handling and monitoring to ensure that no critical compliance task is missed. This makes it important for developers to follow best practices like idempotency, event logging, and failure recovery mechanisms.
Key Technologies and Libraries
Once you know what architecture you'll use, the next step is to pick out the tools that you'll use with it.
Before you choose the tools, you need to understand this: EDD is done when the standard KYC process fails to determine the legitimacy of an entity trying to sign up for your platform. This implies that when you're implementing an EDD pipeline, you must already have a basic KYC workflow in place.
In other words, you've implemented basic data collection for the entity as well as standard checks like verifying age, nationality, and other simpler criteria, but the entity has shown the potential to be high-risk and needs a more thorough examination.
This may require you to get more profile data, which might need to be sourced from third-party providers and cleaned/formatted before you can use it. It could also require you to run more advanced risk-scoring assessments on the profile, something that simple yes/no workflow conditionals can't implement. In any case, you need an advanced business process management (BPM) engine that can handle running standard KYC and complex EDD workflows on the same platform.
API Integrations with Data Providers
To further enhance your profile of the vendor/client, you can connect to external databases such as Dun & Bradstreet for screening against over 460 million company records, sanctions lists, and PEPs. Services like Dow Jones Risk & Compliance also offer access to global databases for sanctions lists, PEPs, and adverse media. You can use APIs provided by these platforms to automatically retrieve data and store it in your databases.
Data Processing Tools
Since the APIs from external data providers often return data in various formats, you need tools that can normalize and clean the data for consistent processing.
For real-time data streaming and analysis, tools like Apache Kafka and Apache Flink are popular choices. Kafka is great for event-driven architectures, enabling real-time data streaming and distribution. It can handle high-throughput scenarios, like monitoring transactions or processing alerts from compliance tools.
Flink helps monitor transaction streams, spot anomalies, and apply rules to flag high-risk activities as events occur. Its ability to process data quickly and integrate with messaging systems makes it perfect for compliance teams dealing with time-sensitive data.
AI/ML Libraries and Frameworks for Risk Scoring and Anomaly Detection
After you have the data you need, you can use machine learning (ML) algorithms (from simple logistic regressors to complex neural networks) that analyze historical data to identify risk patterns and flag anomalies. For example, an ML model could analyze the transaction histories of an entity to identify unusual patterns that might indicate money laundering or fraud. You can also use pretrained models and transfer learning to accelerate development, especially when working with large data sets from diverse sources.
Frameworks like TensorFlow and PyTorch can help you build and train models for various tasks, such as risk scoring, anomaly detection, and pattern recognition.
Rules Engines and BPM Platforms
To put everything together, you need platforms like Drools and Camunda to store the complex rule sets and logic that determine the success or failure of a due diligence attempt.
With these platforms, you can define and manage rule sets without having to hard-code logic into the application, making it easier to update and maintain compliance workflows. For example, a rules engine can help you determine the level of due diligence required for an entity based on factors such as transaction size, jurisdiction, and customer profile.
Most importantly, BPM platforms can coordinate multiple processes and stakeholders, such as triggering additional checks when a high-risk alert is raised or reaching out to internal team members for escalation if needed.
Building an EDD Pipeline
Now that you understand what tools and frameworks you can use to build an EDD pipeline, it's time to try designing one from start to finish.
A typical EDD pipeline could look like this:
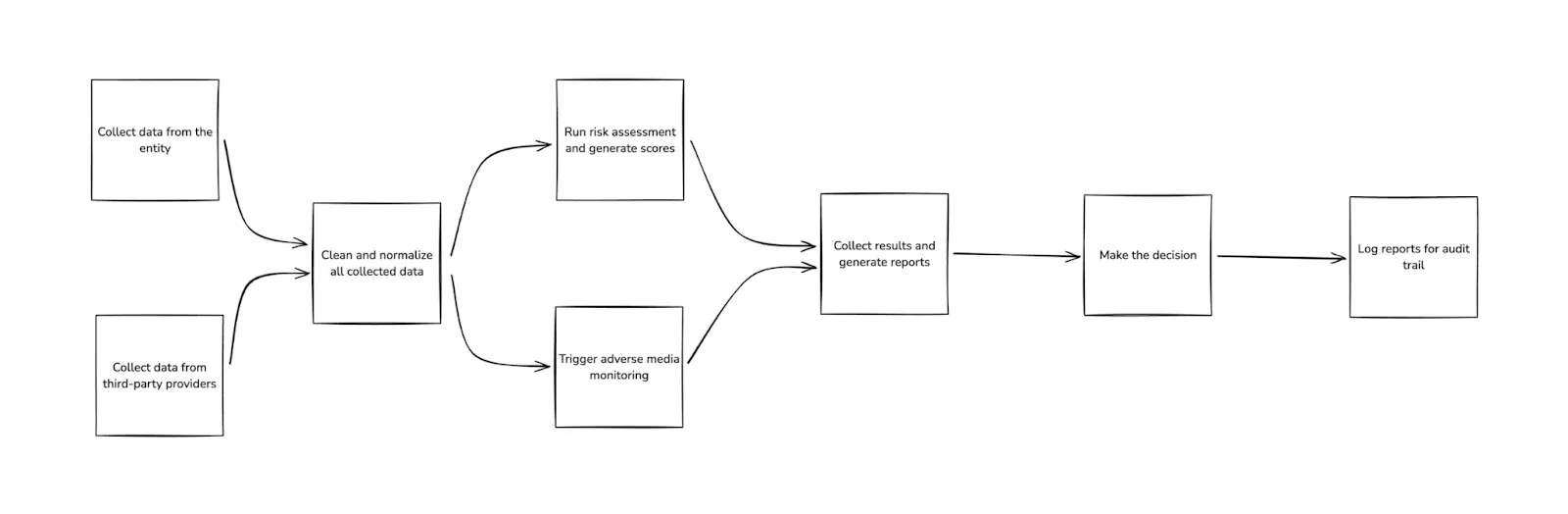
This pipeline contains the following major components:
- Data integration layer to source data from public databases and store all data securely
- Screening and monitoring tools for adverse media monitoring
- Advanced analytics platform to visualize data insights and generate reports for decision-makers
- Decision-making engines to automate checks and coordinate with human reviewers, if needed
- Reporting and documentation solutions to summarize findings and risk assessments
Let's take a look at how each of these components would be implemented in a real-world EDD pipeline.
Data Collection and Storage
The initial data collection is usually done through a web-based application where compliance teams input client or vendor information. Once a record is created, you can use ETL tools like Apache Hop to extract data from multiple sources (like financial records, regulatory filings, and public databases) in real time and store them in scalable databases like PostgreSQL or MongoDB for easy access and management.
This process involves using and integrating multiple data sources and components, which can be time-consuming and difficult to maintain. It's easier to use an automated solution like Prove Identity® that offers vendor/client onboarding and initial screening against global lists such as OFAC SDN, OSFI (Canada), DFAT (Australia), and more.
Data Processing
Once you have the data you need, you need to normalize and clean it so it can be used by other components of the pipeline.
If you're designing an event-based pipeline, you can use a data streaming tool like Kafka to process data as it's collected by the pipeline. For a setup that already has data stored, you can use tools like Apache Spark to batch process and clean it before moving ahead with the pipeline.
Risk Assessment
Once the data has been cleaned and normalized, it's time to run a risk assessment. This component can be as simple as conditional validations or as complex as using K-means clustering to identify customers with similar risk profiles.
The step usually generates a risk score, which helps determine whether the entity should be granted platform access—either through an automated process or manual review. This might not be the only factor that decides the entity's fate, though. An entity with a low-risk score might still need to pass media screening checks if required by regulations.
Media Screening
Parallel to your data processing and risk assessment pipeline, you may also need to carry out adverse media monitoring and screening. You can use AI to continuously scan news sources and databases for negative information about the entities on which you're carrying out due diligence.
You could also implement ongoing monitoring systems that provide updates on changes in risk profiles to ensure compliance. Typical checks include PEP status, adverse media, sanctions, and ultimate beneficial ownership. These data points can change very fast, and you need to keep an eye on them.
You can build monitoring systems from scratch using automation tools like Zapier and UiPath and connect these with databases that provide relevant data, such as sanctions lists or government or corporate registry databases. Alternatively, you could use a solution like Prove to implement ongoing monitoring for your customers.
Analytics and Reporting
Once you have your risk assessment scores and media screening information ready, use platforms like Tableau or Power BI to visualize data insights and generate customizable reports. To take it a step further, you can even deploy engines that utilize machine learning to forecast potential risks based on historical trends and current data inputs.
Decision-Making
The final step is decision-making, where all collected data and insights determine whether the entity should be granted platform access.
This component can be made up of automations and manual diligence. In cases where the entity has clear red flags in its profile or media screening results, you can configure your rules engine to issue an automated rejection. In cases where the entity has a qualifying profile, you can choose to add a final manual review step to double-check everything before giving the green light. It ultimately depends on the regulatory requirements and your organization's overall risk appetite.
Adding More Improvements
Throughout this process, tools like UiPath or Zapier can help you automate repetitive tasks, assign tasks to team members based on workload or expertise, and update project statuses in real time. These tools can even help with slightly more complex tasks, such as screening entities against publicly available sanctions lists and PEP databases. If you use them right, you don't have to worry about coding the logic for these tasks in your pipeline from scratch.
You can also integrate dedicated case management systems to track the progress of due diligence investigations, ensuring accountability and transparency. Don't forget to maintain an audit trail with reporting tools like Power BI and Tableau.
Testing and Validation Strategies
Because a typical automated EDD pipeline contains a variety of components, testing can be complex.
Unit tests can help validate individual modules, such as APIs for retrieving sanctions list data or machine learning models used for risk scoring. These tests should focus on boundary conditions, verifying data accuracy, and edge cases to catch potential issues early in development. Mocking external data sources during unit testing can help simulate real-world conditions without relying on live systems.
Integration tests can help ensure that different parts of the EDD system work together seamlessly. This may involve testing data flows across components like API integrations, rules engines, and streaming platforms such as Kafka or Flink. Your test scenarios should include processing both valid and invalid data to confirm that the system handles errors gracefully and adheres to compliance workflows.
Performance testing is also important for validating how the system handles large data sets and real-time processing requirements. Simulating high transaction volumes or rapid bursts of data can help you check if latency and throughput remain within acceptable limits.
Conclusion
In this article, you explored the importance of automating EDD in regulated industries and the challenges that come with it. You also learned about various tools and frameworks that can enhance your pipelines, from real-time data processing tools to AI/ML libraries that analyze historical data for risk patterns and anomalies. Once you've defined your architecture, selecting the right tools becomes easier.
You also examined the process of designing an EDD pipeline from scratch. Testing your pipeline in complex, often fragile environments is crucial to ensuring reliability.
Prove's innovative solutions can help take your EDD automation to the next level. With the Prove Pre-Fill® solution, you can streamline the three components of KYC—a Customer Identification Program (CIP), CDD, and EDD—through a seamless automated workflow. Learn more about Prove's end-to-end solutions for enhanced due diligence.
The modern
way of proving identity
Trusted by 1,000+ leading companies to reduce fraud and improve consumer

Keep reading
 Read the article: Prove Appoints Industry Veteran Frances Zelazny to Bring Privacy-Preserving Biometrics to Its Identity Platform
Read the article: Prove Appoints Industry Veteran Frances Zelazny to Bring Privacy-Preserving Biometrics to Its Identity PlatformProve has appointed biometrics industry veteran Frances Zelazny as General Manager of New Market Innovations to lead the development of privacy-preserving biometric and KYC compliance solutions. The move expands Prove’s digital identity platform with continuous, quantum-resistant identity assurance designed to combat AI-driven fraud and strengthen trust across the customer lifecycle.
 Read the article: Prove Convenes Inaugural Executive Advisory Board to Define Trust Infrastructure for the Agentic Economy
Read the article: Prove Convenes Inaugural Executive Advisory Board to Define Trust Infrastructure for the Agentic EconomyProve launches its inaugural Executive Advisory Board, uniting banking, payments, and AI leaders to build trust infrastructure for the agentic economy.
 Read the article: When Bots Look Human: A Master Class in Marketplace Trust
Read the article: When Bots Look Human: A Master Class in Marketplace TrustExplore key insights from Marketplace Risk Management Conference leaders at DoorDash and Wolt on how AI-driven fraud, deepfakes, and bot attacks are reshaping marketplace trust and safety. Learn why continuous identity verification and proactive fraud prevention are becoming essential to protecting platform integrity across the entire customer journey.

Trusted by 2000+ leading companies to reduce fraud and improve consumer experiences, Prove is the world’s most accurate identity verification and authentication platform.



